hyu2000
Dissecting “super-human performance” of AlphaGo
When AlphaGo came out, it captured worldwide attention in a five-game series against world champion Lee Sedol. But there were still doubts in the professional Go community. The top Chinese player, Ke Jie, challenged AlphaGo again and eventually came to terms with fate.
Wait, fate?
If you follow the papers on AlphaGo from DeepMind, there are actually only three: the original AlphaGo, AlphaGoZero and AlphaZero (There is also MuZero, but that’s not about Go anymore). The bot did get stronger and stronger, as more experiments were conducted and algorithm improved.
It’s true that human brain is no match for the bot now (I would not attempt that personally). But in terms of Go, what has the bot really achieved?
The Game of Go and Minimax search
In game theory, Go is a two-party, adversarial, deterministic, perfect information game. Fancy terms. But so is Tic-tac-toe. They are the same kind of games in game theory. This means you can apply the same solver to Go as the one for Tic-tac-toe. The only difference is computational complexity.
Even 5x5 Go is surprisingly challenging, for details, check out this post.
But just as in Tic-tac-toe, the game outcome is pretty much determined before you even put the first stone on the board. Here is the true values for opening moves on a 5x5 board (clipped from Werf et al paper Solving Go on Small Boards):
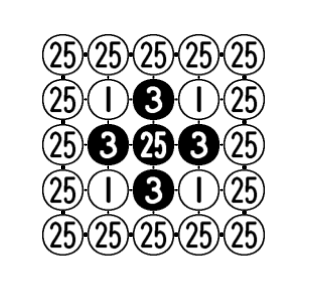
This basically says:
- if black opens on the center of the board, white has no chance to establish even a tiny fief there
- black can also win if it opens right next to the center, by 3 points, if both sides play optimally
- any other opening moves, white wins. Again, assuming both sides play to the best of their ability
Unfortunately, we don’t have the same figure for the 19x19 board. But still, if you have the alien foresight (or as they call it in Dune, pre-science), you will likely have a very different take on the game.
Now, where does AlphaGo fit in this view? Is it still pathetically searching in the dark?
Before the bot arrived, Go was the domain of human experts. Many books were written on strategies and tactics; kids went to Go schools to learn the trade. Major international Go touraments were a matter of national pride. Looking back, that feels like stone age.
With AlphaGo, we are at the super-human level. But don’t let that title fool you. Imagine an alien civilization, either with better computing device, or superior reasoning, has figured out the minimax value of 19x19 Go. To them, AlphaGo would look like a bot in dark ages.
Ever improving performance in AlphaGo
[AZ Elo vs #iterations] As AlphaGo team and several others showed, the bot kept getting stronger and stronger with more iterations. After it got past human-level performance, we lost interest at some point and had to pull the plug.
On a more technical level, with the same neural network architecture, AlphaGo’s performance will likely saturate at some point. Then we add more parameters (more blocks/filters), to give it room for improvement.
So, you want to beat AlphaGo…
Well, you have several options. One is to keep training on top of the latest AlphaGo model for several more iterations, if you are DeepMind. If you are not, there are a few open-source clones: MiniGo, ELF OpenGo and KataGo. Some of them claimed to be the strongest model at various point in time. The bot-vs-bot race is almost an arms race on computational resources.
A more interesting alternative is to target the model’s weakness directly. As all programmers know, nothing is perfect: bugs in the code, weaknesses in algorithms. DeepMind actually published a paper in 2020: “Approximate Exploitability: Learning a Best Response”, which mentioned an interesting exploit on AlphaGo. More on this later.
The thing is that AlphaGo covered most of the bases pretty well. If you are DeepMind, you may know some of its design weaknesses. If you are not, one has to rely on algorithms to search for its weakness. Again, it’s an arms race.